Daniel
Daniel show english version
show english version 
Dass KI Texte schreiben oder auch Bilder malen kann, hatte ich schon öfter gelesen. Bisher hatte ich immer gedacht, das könnte man nur über Webservices wie GPT-3 oder DALL-E von (kommerziellen) Anbietern ausprobieren.
Positiv überrascht hat es mich daher, dass es auch GANs gibt, die auf dem heimischen Rechner laufen - sofern die Grafikkarte über entsprechende Leistung und spezielle Treiber wie z.B. CUDA verfügt.
Beim verwandten Thema "Deep-Fakes" hatte ich bereits vor ein paar Jahren mit einer noch älteren Grafikkarte erfolgreiche Experimente gemacht. Ich war also guter Dinge 😀.
Bei meinem ersten Versuch in 2021 wollte ich dann gleich "in die Vollen" gehen und ein GAN selbst trainieren. Dazu muss man wissen, dass das Training des Modells in der Regel der rechenintensivere Teil ist. Die spätere Nutzung benötigt dann vergleichsweise wenig Rechenpower. In meinem PC steckt eine GeForce GTX 1080 TI mit 12 Gigabyte GPU-Speicher. Diese bringt zwar schon ganz gute Leistung, ist aber für KI-Training bestenfalls Mittelmaß. Das sollte mich aber nicht abschrecken, denn ich dachte mir: Wenn die Grafikkarte nicht genug Leistung hat, dann muss man halt einfach etwas länger warten.
Eine eigene Selfie-KI
Meine erste Idee war: Warum trainiere ich mir nicht eine KI, die Selfie-Fotos von mir erfindet - dann muss ich keine eigenen Selfies mehr machen 😉. Zufällig hatte ich die letzten Jahre über genau das getan, nämlich (angespornt durch eine entsprechende Smartphone-App) regelmäßig Selfies gemacht. Dadurch hatte ich bereits eine Menge an Trainingsmaterial vorliegen.
Das passende Werkzeug dafür war ein StyleGAN auf der Basis von TensorFlow. Ein solches GAN aufzusetzen war überraschend leicht - auch wenn ich beim ersten Mal fast zu spät gemerkt habe, dass man sich durch die ganzen Python-Dependencies den PC "versaut". Besser man verwendet virtuelle Environments oder gleich das Tool Anaconda.
Ernüchternd war dann aber die Wartezeit beim Training, obwohl mein PC Tag und Nacht durch auf voller Leistung (und Lüfter!) rechnete. Auch nach zwei Tagen konnte das Modell Gesichter erst sehr schemenhaft erzeugen:

Nach zwei weiteren Wochen(!) konnte man schon grob erkennen, wohin es wohl gehen sollte. Allerdings könnte der Unterschied "Brille/keine Brille" vielleicht ein Problem werden. Die Ergebnisse wurden so langsam auch etwas creepy...

Noch einmal eine Woche später zeigte sich ein interessanter Mix: Ein paar wenige Bilder waren schon ziemlich nahe dran an einem echten Foto, während viele noch ganz offensichtliche Fehler hatten. Die Brille schien hingegen der ersten Trainingsergebnisse wohl doch kein großes Problem zu werden.

Nach einer weiteren Woche Trainingszeit begann das Netz beim Training mittendrin und recht zufällig mit mathematischen Rechenfehlern abzubrechen. Das ließ sich durch Zurückspringen auf einen früheren Stand des Modells und neuem Training ab diesem Stand beheben. Ab da hing dieses Problemaber als Damoklesschwert über dem Training und kostete noch mehr Rechenzeit als bisher schon. Wenn man regelmäßig morgens sieht, dass das Training mitten in der Nacht ohne Ergebnis abgebrochen wurde, demotiviert das schon etwas.
Als proof-of-concept und für meinen eigenen Forschergeist genügte mir das Ergebnis aber, so dass ich kein neues, mehrwöchiges Training gestartet habe. Das letzte, erfolgreiche Model konnte (nach insgesamt 4.5 Wochen Training) Selfies wie diese hier erzeugen. Immer noch ziemlich gruselig - aber auch erstaunlich, was eine KI so von sich aus trainieren kann:

Was ich dabei spannend finde: Oft wird gesagt, die trainierten KI-Modell ließen keine Rückschlüsse auf das Trainingsmaterial zu. Statt dessen würden sie das Material nur "irgendwie" abstrakt verarbeiten und dann aus dem selbst erlernten ganz neue Dinge erzeugen, die nichts mehr mit den einzelnen Rohdaten zu tun hätten. Zumindest für diese Art von Netzen scheint das aus meiner Sicht nicht ganz zuzutreffen. Ich kann in den meisten Bildern nämlich auch den erzeugten Hintergrund des Bildes wiedererkennen: Sowohl das mit Notizzetteln beklebte Whiteboard im Büro als auch das blaue Ikea-Regal und die Tapete in meinem Arbeitszimmer tauchen immer wieder erkennbar auf. Was ja an sich auch logisch erscheint, denn auch diesen Bestandteil des Bildes muss die KI ja aus ihrem trainierten Model heraus erzeugen können.
Bilder per Texteingabe generieren
Spannend finde ich auch KIs, die ein Bild auf Basis einer reinen Textbeschreibung erzeugen. Je nach Qualität der Bilder fällt es manchmal schwer, jemandem zu erklären, dass der Computer diese Bilder auf Basis rein mathematisch-statistischer Verfahren aus Trainingsdaten generiert hat - und nicht wirklich inhaltlich "verstanden" hat, was der vorgegebene Text bedeutet.
Auch hier gibt es einige Programme und Modelle, die man lokal und ohne Internetverbindung auf dem eigenen PC ausführen kann. Mit den meisten dieser KIs kann man auch Dinge wie "Style Transfer" durchführen, also ein vorhandenes Bild oder Foto im Stile eine bestimmten Künstlers nachzeichnen lassen. Oder man kann Teile aus Bildern heraus retuschieren, indem man die KI den fehlenden Bereich neu generieren lässt.
Hier habe ich mir ausschließlich mit der Funktion "Bild aus Text erstellen" beschäftigt. Die verschiedenen KIs sollten folgende Bilder erzeugen:
- French fries on the beach with sailboats in the background.
- A cat laying on a car in front of a beautiful sunset.
- A squirrel at a computer in a server room, with lots of colorful lights.
- Nikola Tesla holding a battery on a hill during a thunderstorm.
Wahlweise wurden die als Gemälde und/oder als Foto ausgegeben - je nach Fähigkeit der KI.
VQGAN-CLIP - erstellt eher abstrakte Bilder
Für meine ersten Versuche nutzte ich VQGAN-CLIP, das auf Pytorch basiert. Es stehen zahlreiche trainierte Modelle zur Verfügung, wie z.B. vqgan_imagenet, wikiart_16384, sflckr oder coco.
Die Ergebnisse waren vom Stil her eher abstrakt - vielleicht ganz gut zu beschreiben wie die Motive von sehr künstlerischen Postkarten:
French fries on the beach with sailboats in the background.
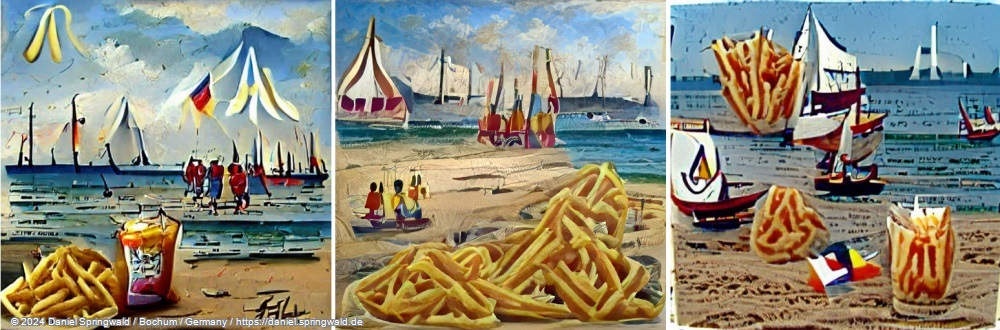
A cat laying on a car in front of a beautiful sunset.

A squirrel at a computer in a server room, with lots of colorful lights.

Nikola Tesla holding a battery on a hill during a thunderstorm.

Latent Diffusion Models (LDM)
Die nächsten Bilder sollten Latent Diffusion Models erzeugen, die auf pytorch und taming-transformers basieren. LDMs können erkennbare Motive erzeugen, die zum Teil durchaus realistisch wirken. Interessant finde ich dabei, dass manche Bilder auch eine weiße, unleserliche Bildunterschrift oder eine Art "Shutterstock"-Wasserzeichen bekommen haben.
Hier die Ergebnisse der LDMs:
French fries on the beach with sailboats in the background.


A cat laying on a car in front of a beautiful sunset.


A squirrel at a computer in a server room, with lots of colorful lights.


Nikola Tesla holding a battery on a hill during a thunderstorm.


Weitere nützliche Links zu LDM:
Dall-E mini
Auch DALL·E mini kann man kostenfrei auf dem eigenen PC betreiben. Es gibt zudem auch eine kostenfreie Online-Version auf huggingface.co.
Die generierten Bilder sind meiner Meinung nach tendenziell etwas weniger gelungen als bei den Latent Diffusion Models. Die Motive neigen oft zum Abstrakten oder sehen auch mal wie eine Kinderzeichnung. Zwischendurch sind aber auch immer wieder fast fotorealistische dabei, wie hier bei den Katzen.
French fries on the beach with sailboats in the background.


A cat laying on a car in front of a beautiful sunset.


A squirrel at a computer in a server room, with lots of colorful lights.


Nikola Tesla holding a battery on a hill during a thunderstorm.

Disco Diffusion v5 Turbo
Die letzte von mir ausprobierte KI war Disco Diffusion v5 for Windows.
Die Themen der Motive sind in den Bildern in der Regel gut erkennbar, werden aber oft etwas psychodelisch und erinnern mich dann an DeepDream. Die Motive werden dann mehrfach und überschneidend in die Strukturen des Bildes eingebaut. Bei meinen Versuchen waren (insbesondere beim Fotos-Output) bei Weitem nicht so realistisch, wie die der LDMs oder von Dall-E-mini. Manche Ergebnisse wie die "French Fries" haben mich aber ziemlich begeistert - insbesondere die Gemälde sehen meiner Meinung nach recht künstlerisch aus.
Hier die Ergebnisse für Disco Diffusion v5 Turbo:
French fries on the beach with sailboats in the background.



A cat laying on a car in front of a beautiful sunset.



A squirrel at a computer in a server room, with lots of colorful lights.


Nikola Tesla holding a battery on a hill during a thunderstorm.

Nützliche Links zu Disco Diffusion v5 Turbo
- Get Started With Disco Diffusion to Create AI Generated Art
- Disco Diffusion Modifiers
- Disco Diffusion AI Guide
- Zippy's Disco Diffusion Cheatsheet v0.3
- Generate a Music Video from song lyrics
- Disco Diffusion: How I Play With Prompts
- progrockdiffusion zum Ausführen in der Konsole
Funktionsweise
Wer sich für für Funktionsweise interessiert - hier ist eine schön gemachte Erklärung:
Bonus Material